
Table of Contents
April 23, 2025 Update: I’ve updated this post to reflect all publisher partnerships with AI companies as of April 23, 2025. OpenAI and Microsoft have been busy.
- LLMs used by OpenAI and Google are heavily curated datasets.
- Ziff Davis’ study shows that heavily curated datasets contain a higher proportion of high-DA websites.
- WebText (used to train OpenAI’s GPT-2) contains high-DA websites.
- OpenWebText 2 (expanded version modeled after WebText) also contains high-DA websites.
- AI companies have many partnerships with these high-DA publishers.
Getting featured on AI results like ChatGPT is still a mystery.
I have been hypothesizing about how employing more digital PR will increase the likelihood of getting your brand mentioned in an LLM (see link building in 2025), but I have yet to find a compelling study to back it up.
Until now.
A new study by researchers at Ziff Davis shows that LLMs may prioritize data from authoritative, high-DA (Domain Authority) publishers.
Taking it a step further, we may be able to tell what publishers these LLMs prefer based on the partnerships they’ve formed.
Here is what the current landscape looks like today:

If the above is confusing, follow along with me as I help to connect the dots.
If you’re a LLM newb like me, you might want to read this next primer section; if not, skip to the main findings section.
LLMs for Dummies (like me!)
Large Language Models are designed to generate, predict, and interpret your text. Some common LLMs you might have heard of are OpenAI’s GPT series, Google’s LaMDA, and Meta’s LLaMA.
They get trained from enormous datasets like text from the internet, books, and others.
For instance, one of the datasets used, OpenWebText2, is curated by scraping URLs linked on Reddit posts with a three or higher score.
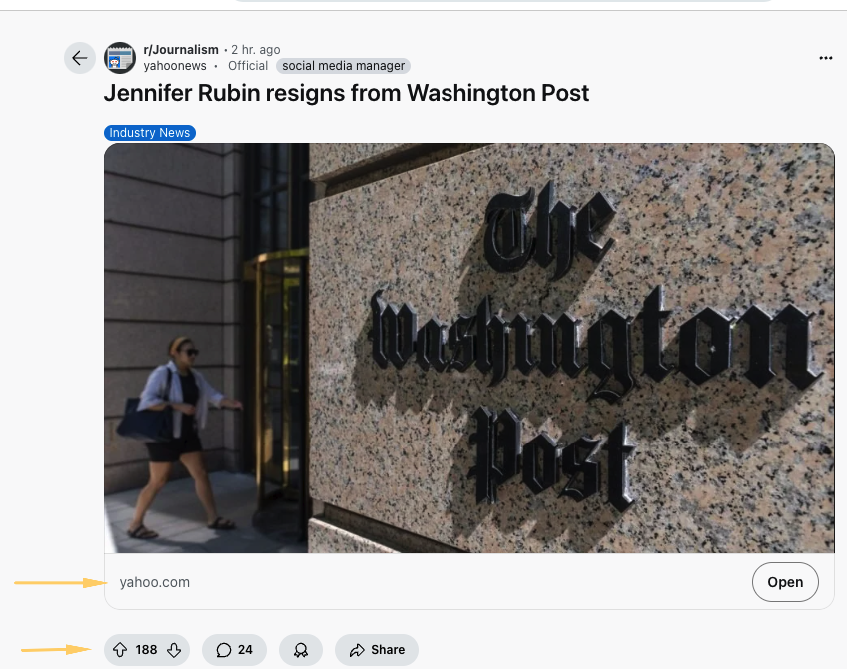
So, a URL like this one from Yahoo would show up based on the high “score”:
As I said in the intro, LLMs don’t work like search engines, nor do they “know” things like you’re led to believe in the movies.
They get trained to predict text by analyzing patterns in these massive datasets.
What Datasets Do LLMs Use?
We don’t know exactly what datasets LLMs use. However, there is some history to lean on, which we can use to infer their current methods.
For example, OpenAI openly disclosed the dataset they used to train GPT-2 (we are on GPT-4 now).
We can also point to relationships with publishers regarding where they are getting the data used to train their datasets.
Here are two other things to know:
Most Datasets Get Curated
You saw what happened when Google’s initial launch of AI Overviews relied too heavily on Reddit:
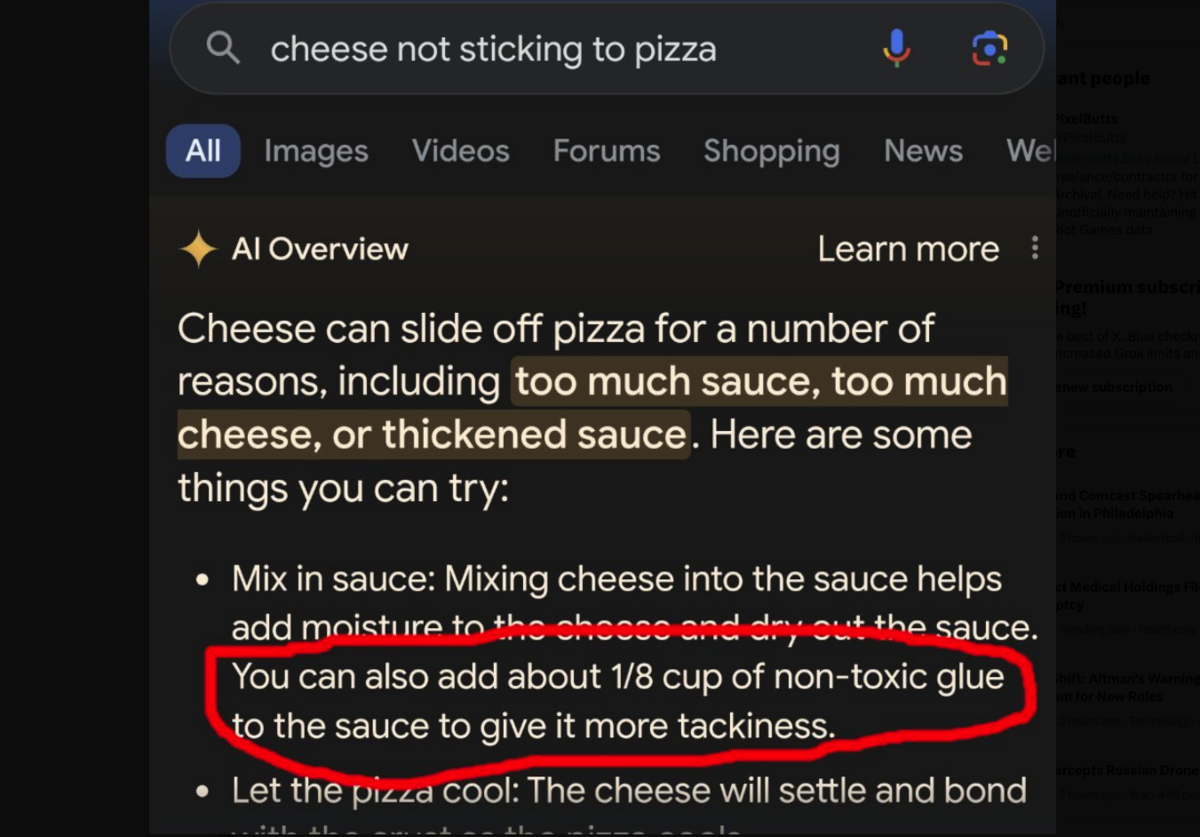
So, because some of the data gets pulled from places like Reddit, the datasets need curation to ensure better, higher-quality results.
Raw datasets like Common Crawl have little to no curation.
Heavily-curated datasets, such as OpenWebText or C4, filter out low-quality content and prioritize high-authority, relevant, and clean text.
The extent of curation varies widely among datasets.
Most LLMs Get Trained on a Mix of Datasets
To ensure quality and depth, LLMs use a mix of data.
As mentioned, we don’t know precisely what datasets each technology uses—especially from an ever-evolving field like AI.
As the Ziff Davis study says, “Major LLM developers no longer disclose their training data as they once did.”
Here’s a snapshot of what we know:
| Dataset | Source | Curation Level | Accessibility | Usage Examples |
|---|---|---|---|---|
| WebText | Reddit links (≥3 upvotes) | High (human-curated) | Proprietary (OpenAI) | GPT-2, GPT-3 training indirectly |
| OpenWebText | Reddit links (replicated method) | Moderate | Open-source | Research, proxy for WebText |
| OpenWebText2 | Reddit links (longer timeframe) | Moderate | Open-source | Proxy for GPT-3’s WebText2 dataset |
| C4 | Cleaned Common Crawl data | Moderate | Open-source | Google T5, LaMDA |
| Common Crawl | General web crawl | Minimal | Open-source | Broad AI training, including GPT-3 |
OK, next, let’s look at what Ziff Davis showed us.
What Did The Ziff Davis Study Show Us?
Ziff Davis, the publishing company behind sites like IGN.com and Mashable.com (and Moz.com), cross-referenced a list of publishers with the URLs that appear in LLM training datasets.
The sets are:
- Common Crawl
- C4
- OpenWebText
- OpenWebText2
- WebText
Their findings are below:
There is a High Percentage of Publisher URLs in Datasets
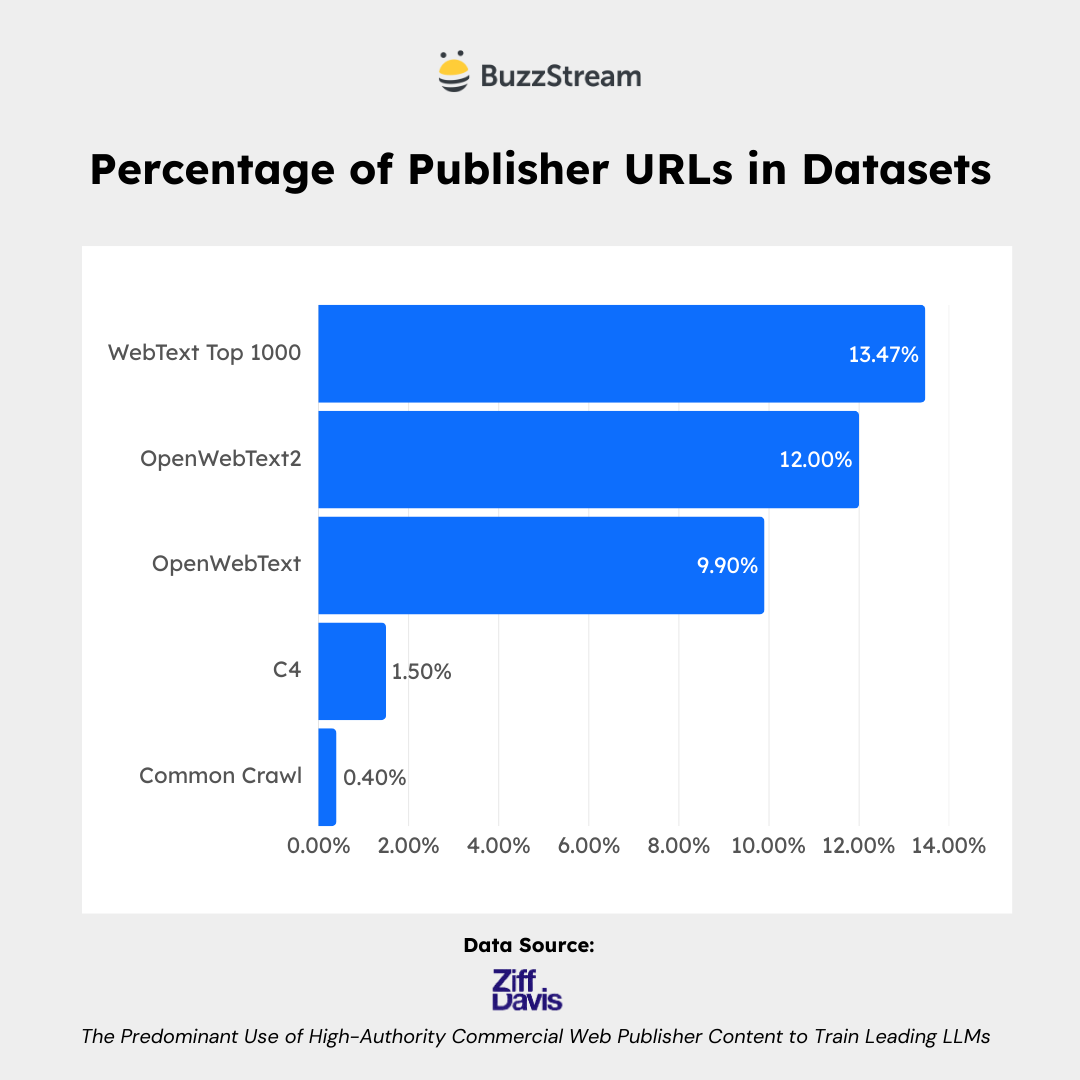
As you can see, there is a much higher concentration of publisher URLs in the highly-curated WebText and OpenWebText2 datasets.
Then, they looked at the Domain Authority (DA) of these URLs to gauge the usage of high DA sites in these datasets:
There is a High Concentration of High DA URLs in Curated Datasets
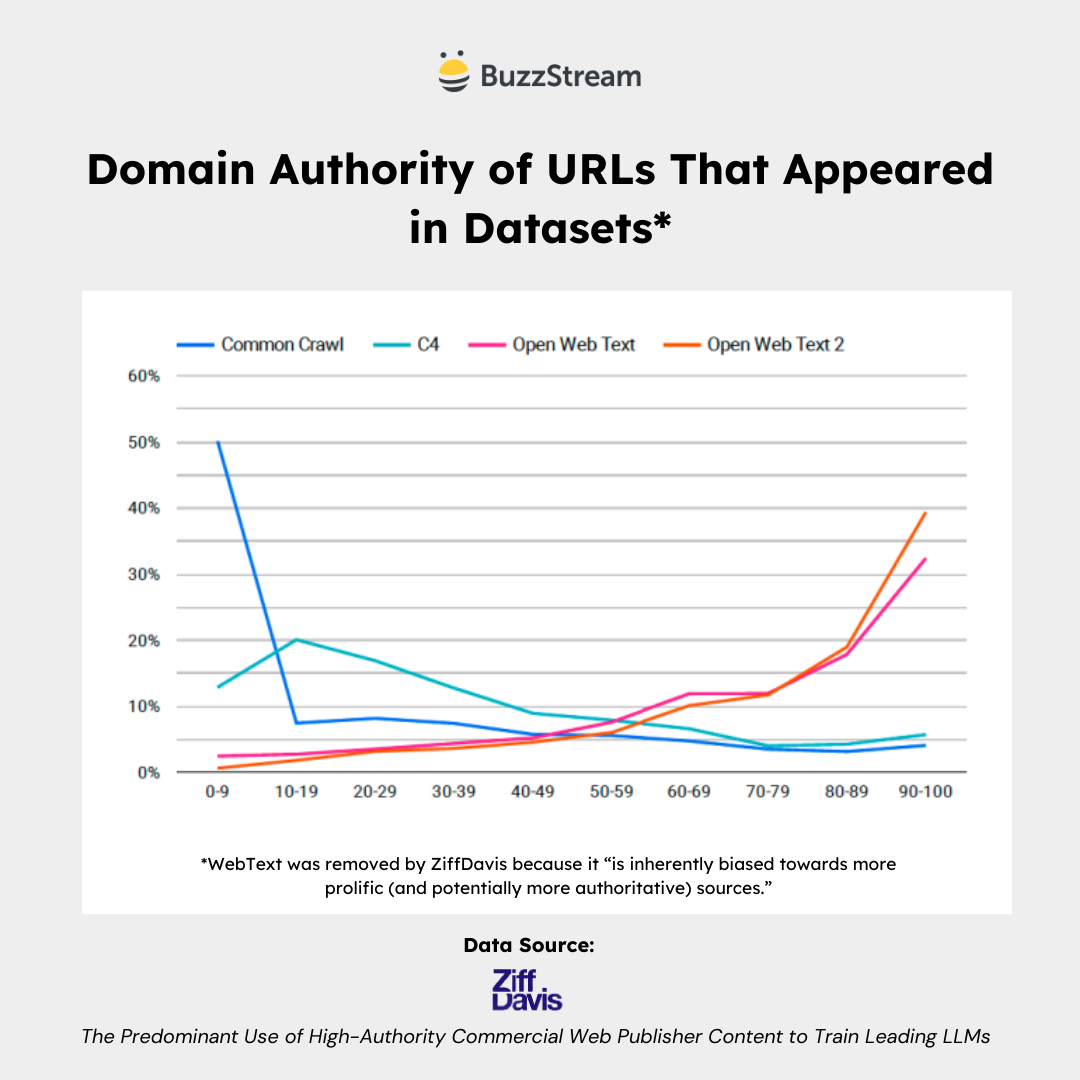
The highly curated sets of OpenWebText and OpenWebText 2 contain higher amounts of high DA URLs.
The big takeaway is that the data used to train early ChatGPT versions (and those modeled after the datasets) contained a high percentage of high DA sites.
What Do AI Companies’ Partnerships With Publishers Tell Us?
As I mentioned, we don’t know precisely what AI technologies like GPT-4 use as datasets.
Still, they’ve used highly curated datasets with a high concentration of high-DA publisher sites.
So, let’s look at the partnerships between the top AI companies and publishers.
(You may want to wear your tinfoil hat for this next part.)
OpenAI Has Partnerships With 16 Major Publishers

Based on my research, OpenAI has the most, with 16 reported partnerships with publisher sites. But Google (Gemini) and Microsoft (CoPilot) also have several.
As of the publishing of this article, here is a list of the publishers who have partnerships with AI:
| Publisher | Date Announced | AI Partner |
|---|---|---|
| Associated Press | July 13, 2023 | OpenAI |
| Axel Springer | December 13, 2023 | OpenAI |
| Le Monde | March 13, 2024 | OpenAI |
| Prisa Media | March 13, 2024 | OpenAI |
| Financial Times | April 29, 2024 | OpenAI |
| News Corp | May 22, 2024 | OpenAI |
| May 16, 2024 | OpenAI | |
| Dotdash Meredith | May 7, 2024 | OpenAI |
| Vox Media | May 29, 2024 | OpenAI |
| The Atlantic | May 29, 2024 | OpenAI |
| Condé Nast | August 20, 2024 | OpenAI |
| Future plc | December 5, 2024 | OpenAI |
| Hearst | October 8, 2024 | OpenAI |
| The Guardian | February 14, 2025 | OpenAI |
| Axios | March 25, 2025 | OpenAI |
| The Washington Post | April 22, 2025 | OpenAI |
| Financial Times | October 1, 2024 | Microsoft |
| Reuters | October 1, 2024 | Microsoft |
| Axel Springer | October 1, 2024 | Microsoft |
| Hearst Magazines | October 1, 2024 | Microsoft |
| USA Today Network | October 1, 2024 | Microsoft |
| HarperCollins | November 19, 2024 | Microsoft |
| Associated Press | January 12, 2025 | |
| February 22, 2024 | ||
| Stack Overflow | February 13, 2024 |
You can then look at the concentration of these publishers found in the datasets reviewed by Ziff Davis.
Here is the percentage of high-DA sites that appear in WebText (the curated dataset used to train GPT-2, which was openly disclosed):
Partnered Publishers Show Up Frequently in WebText
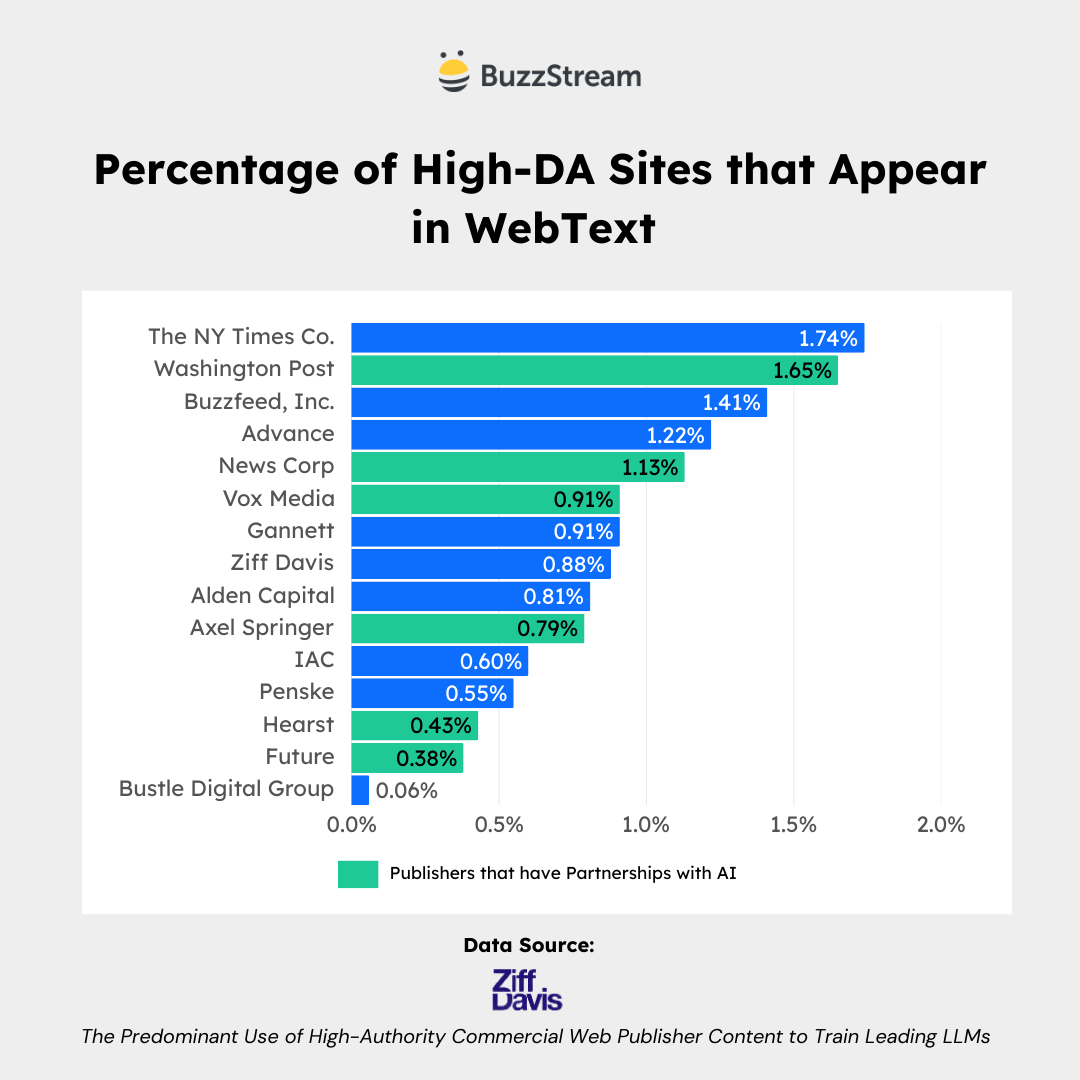
You can see the high usage for News Corp, Vox Media, and Axel Springer, all of which have partnerships with OpenAI.
Here it is for OpenText2:
Partnered Publishers Show Up Even More Frequently in OpenText2
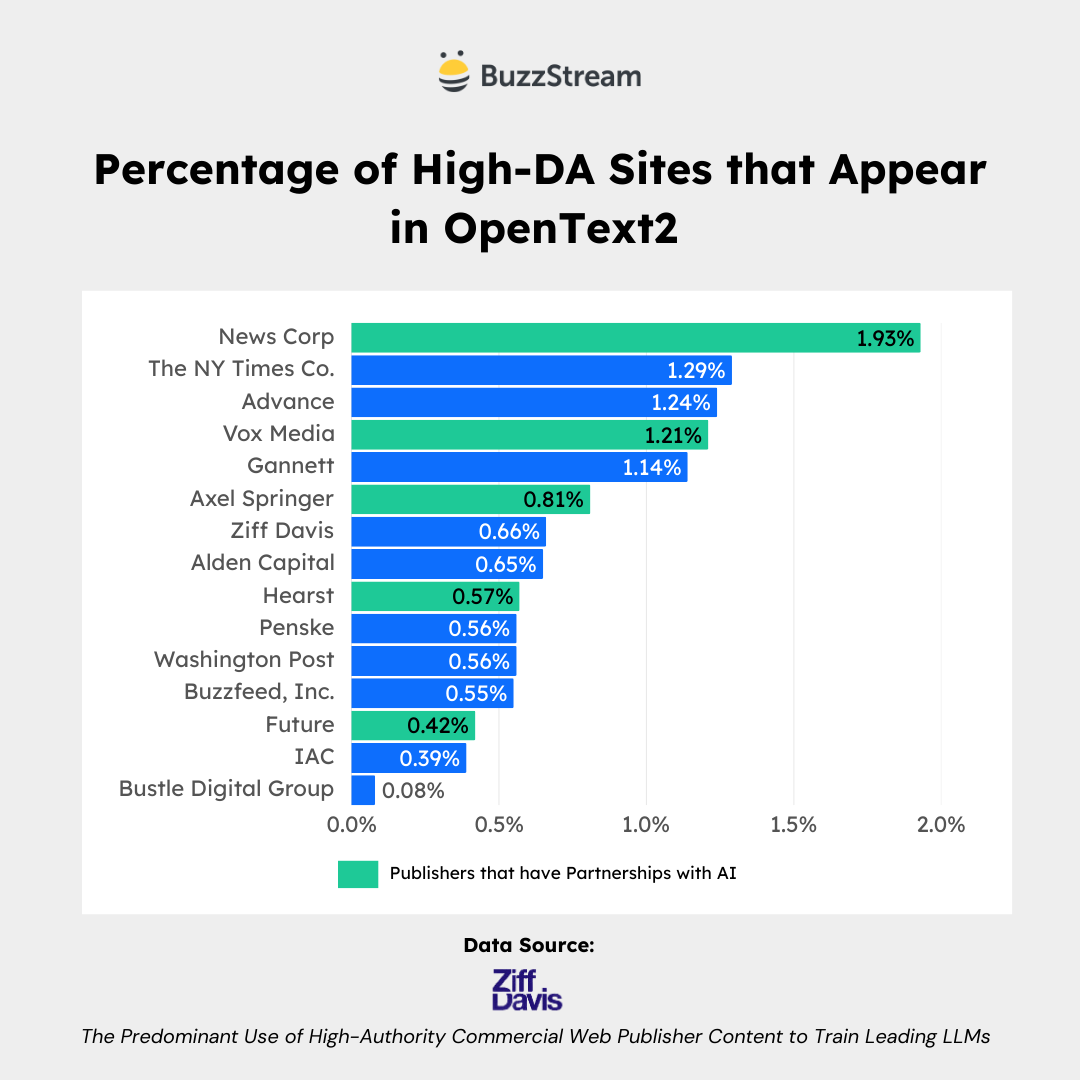
This similar breakdown of the URLs that appear in OpenText2 shows News Corp, Vox Media, and Axel Springer all in the top 10.
With those in mind, here is a spotlight on OpenAI’s partnerships with publishers that also appeared in those early training datasets:

Again, we are taking some big leaps here.
And in the next section, I’ll tell you what you can (and should) do with this information.
What Should PRs and Link Builders Learn From This?
In short, get links and mentions from high-end news sites if you want to win in 2025 and beyond.
I know that isn’t earth-shattering news for most of you reading this, but it does add another arrow to your quiver when pitching or investing in digital PR.
Should you run out to get a link from NewsCorp in hopes that you appear in ChatGPT results?
I’m sure it’s not that easy.
OpenAI and other technology companies don’t want us manipulating their datasets (in the same way that Google doesn’t want us trying to manipulate search results.)
That said, here is what you should do:
Get Links from High DA Publishers
Again, I want to be abundantly clear that while this study is as close as it gets, it doesn’t directly tell us that getting links from high DA sites means you will show up in AI results.
But we know they curate their sets by leaning on high DA news sites.
We also know that they are partnering with a lot of publishers.
That said, there is at least compelling evidence that high DA sites are being used to train the datasets, so I feel confident enough to push for links and coverage from those sites.
Future-Proofing Presence in AI is Being Human
This study is just one of many to come out recently that will continue to set the groundwork for PRs in 2025 and beyond.
Trying to extract loopholes and hacks from these studies is tempting.
But I urge everyone not to lose sight of the big picture. Humans are at the other end of the computer, reading your content and news.
Those are the ones you should be writing to and engaging with, not LLMs, search engines, and other machines.
 Check out the BuzzStream Podcast
Check out the BuzzStream Podcast






